Tokenization vs. Embedding: Understanding the Differences and Their Importance in NLP

Tokenization takes the text and maps input sequences to numbers. okenization Straight mapping from token to numbers ( can be modeled but quickly gets too big). These tokens are usually words that can also be phrases, punctuation marks, or even individual characters. Tokenization is the first step in NLP and is essential for text preprocessing. Tokenization helps in preparing the text data for analysis by making it more structured and easier to work with.
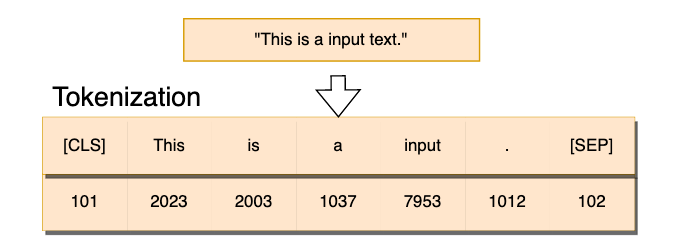
There are different approaches to tokenization, such as rule-based and statistical-based methods. In the rule-based method, tokenization is done based on pre-defined rules such as white spaces, punctuation marks, and other grammatical structures. On the other hand, the statistical-based method uses machine learning techniques to learn from the data and identify the most appropriate tokenization approach.
For instance, consider the following sentence: “I love NLP!” The rule-based tokenization would result in the following tokens: [“I”, “love”, “NLP”, “!”]. While the statistical-based approach would consider context and possibly tokenize the sentence as [“I”, “love”, “natural”, “language”, “processing”, “!”].
Embedding turns mapping of the input text vector to the embedding matrix. embedding does a richer representation of the relationship between tokens ( can limit size + can be learned). Embedding, on the other hand, is the process of representing words or phrases as vectors in a high-dimensional space. These vectors are often referred to as embeddings. Embeddings capture the semantic meaning of the words or phrases and their relationships in the text. They are usually created using machine learning techniques such as Word2Vec or GloVe.

Embeddings are powerful tools that help to improve the performance of NLP models. By representing words as vectors, embeddings enable the models to capture the context and meaning of the text. For example, consider the words “king,” “queen,” “man,” and “woman.” These words are related, and their relationships can be captured using embeddings. In an embedding space, the vector difference between “king” and “queen” would be similar to the vector difference between “man” and “woman.”
